


Hello Veda Team,
We'd like to adress a problem we have.
Error Message:
-„Databases too big“
Model:
-Pan European TIMES (30 regions model)
-2664 prc and 809 commodities
- ca. 450 UC’s per country
Description of the problem:
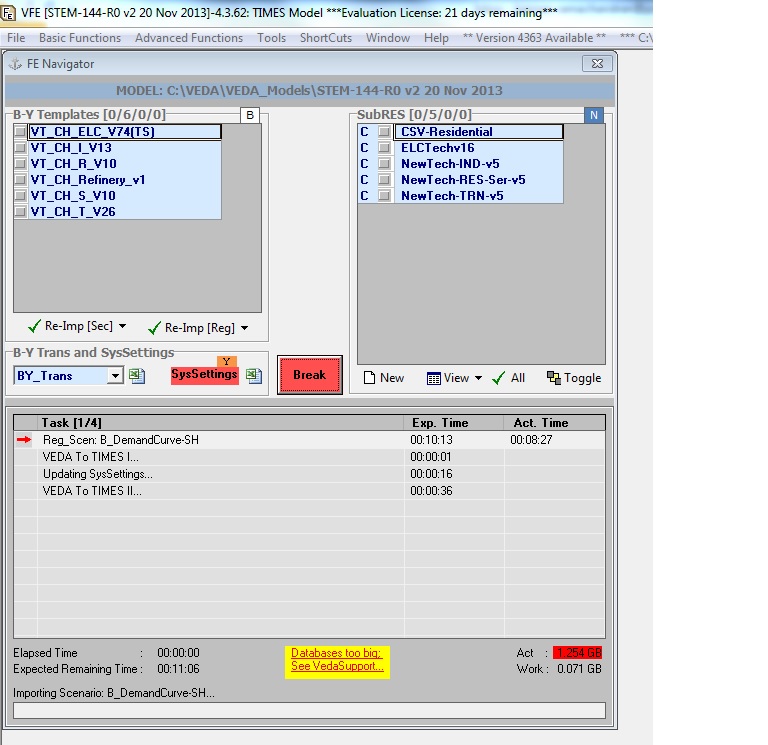
-When we build a database we receive the error message “Databases too big”
-This happens (for example) at the step “VEDA to TIMES II …” at the sizes of ACT: 1.205GB, WORK: 0.513GB when we synchronize this one single Scenario file
What we tried to solve the problem:
-We split the construction of a new VEDA-FE database into different steps, integrating just the BY-Templates and the B-NEW-Techs in one step, then synchronizing this step and taking it as a base for all other steps where we just add one additional Scenario file (so we can’t make smaller steps)
-We also tried to increase the number of interpolated values, but also this doesn’t work
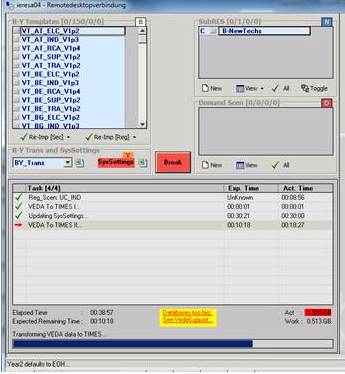
Results:
-Even with this approach the databases are too big (so we can’t build up a database any more)
Question:
-Are there any possibilities to use bigger databases and to create a new database for a large model in one step?
Would it be possible to migrate to an integrated SQL-Database? The current version of SQL Server 2008 R2 Express Edition supports one processor, one GB RAM and a max. DB size of 10 GB.
As we have seen, none of the established DB reaches the max size of 2GB. Why do ‘ActiveDB.MDB and VFE_Work.MDB not use the max limit of access.
Your reply is very much appreciated,
mc


 something new to me. Thanks
something new to me. Thanks 